Haremos referencia al término "High Availability" (alta disponibilidad) en los sistemas de cómputo, principalmente nos referiremos a los sistemas de Bases de Datos que garantizan el continuo funcionamiento de los aplicativos.
Situación actual
Hay un gran porcentaje de sistemas comerciales sobre internet que DEBERIAN de proporcionar un funcionamiento ininterrumpido de sus aplicaciones en diferentes sectores laborales, mencionaré algunos que son extremadamente críticos en su día a día para usuarios finales, y para el negocio mismo, por ejemplo: Sistemas Bancarios, de Seguridad Social, Telecom, Financieros, Energía, Seguros, Educación, Manufactura, Alimentos y bebidas, e-Commerce, IT, Medios y Entretenimiento, etc, por solo mencionar algunas de las ramas vitales en donde la intermitencia del sistema (sin ir siquiera a alto total del funcionamiento) causaría grandes daños tantos financieros, los daños son tanto para quien ofrece los servicios como quien recibe el servicio; es decir, habría daños tanto del usuario final (cliente) como de quien proporciona el servicio (proveedor).
En dónde empieza la "High Availability"
La alta disponibilidad empieza en todas las capas del centro de cómputo, desde tener redundante las bbdd hasta las tarjetas de red y los Web Servers.
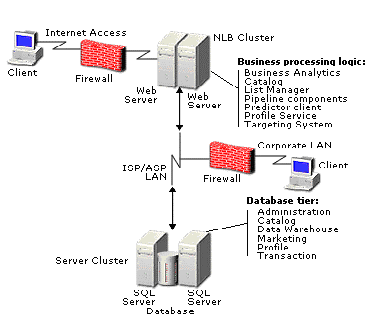
Riesgos de no implementar una metodología de "High Availability"
Los riesgos de no proporciona una solución segura para manejar su alta disponibilidad pueden impactarle severamente en: Costos Monetarios, Legales y de Difamación, Mala reputación (del cual hay que trabajar mucho para poder recuperar la buena fama), inclusive se puede llegar hasta la pérdida del negocio o peor aún, llegar a pagar bastante tiempo en prisión por negligencia profesional.
Costos de implementar "High Availability"
A continuación se expondrán algunos escenarios que ilustran en no pensar en la alta disponibilidad:
“ ,,,, en las últimas semanas sobre el tiempo de inactividad de la red, muchos han preguntado "¿Cuál es el costo del tiempo de inactividad de la red?" Basado en encuestas de la industria, el número que normalmente citamos es de $ 5,600 p / minuto, que extrapola a más de $ 300K p / hora (Dave Cappuccio).
Sin embargo, esto es solo un promedio y existe un alto grado de variación, en función de las características de su empresa y su entorno (es decir, su vertical, tolerancia al riesgo, etc.). Por ejemplo, este estudio de Avaya indica que el rango es de $ 140K a $ 540K p / hora.”
Es importante medir el riesgo/impacto que tendrá el negocio por falta de servicio, esto es importante delimitar pues en base a eso serán las medias que se implementaran para garantizar la alta disponibilidad de su sistema, los riesgos pueden ser:
- Critico
- Alto
- Medio
- Bajo
- Nota al margen
Corrección del riesgo
Una vez que nos hemos quedado sin sistema, tenemos que medir en cuanto tiempo podemos estar de nuevo en línea, con todos los daños colaterales que esto conlleva:
|
Tiempo en Recuperación |
Severidad |
Nota |
|
Segundos |
mínima |
Revisar si no hay pérdida de información. |
|
Algunos minutos |
Crítico |
Revisar si no hay impactos colaterales |
|
Hora/s |
Altamente crítico |
perdidas monetarias, demandas legales y mala reputación |
|
Un día |
No tolerable |
Estas fuera del negocio y con pago de multas |
¿Qué es lo que Oracle tiene para manejar la "High Availability"?
Oracle líder en el mercado de IT, proporciona bastas soluciones a diferentes niveles para garantizar la alta disponibilidad desde:
- Redundancia a nivel de disco. (ASM)
- Redundancia a nivel bbdd. (Data Guard, Real Time Query, Golden Gate)
- Redundancia a nivel de server. (RAC, Application Continuity)
- Replicación Simétrica Avanzada entre bbdd. (Streams, Golden Gate)
- Redundancia en Respaldos (rman, Oracle Secure Backup, Zero Data Loss, Flashback, )
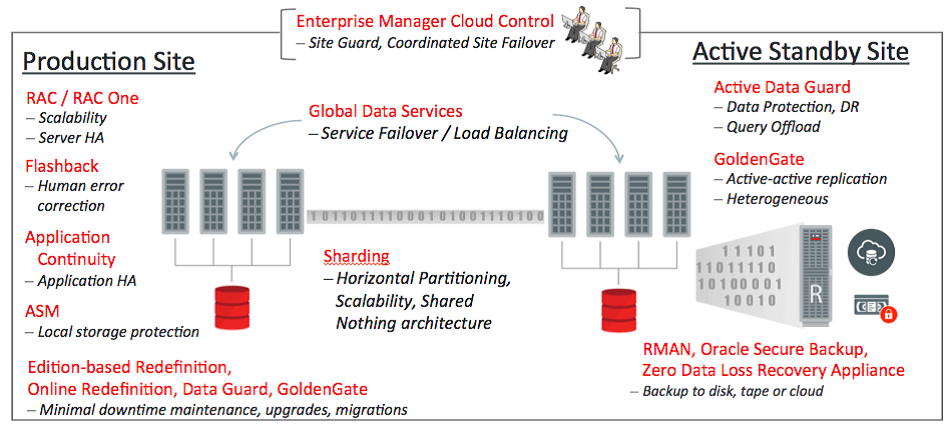
Conclusiones
Los responsables de los centros de cómputo deben de tener presente los impactos en costos por tener fuera de línea los sistemas; siempre será mayor el gasto por no tener una metodología de “recovery” y continua disponibilidad ante una desastre.
“Hay que recordar que los Centros de Cómputo, los servidores, los discos llegan a fallar, es utópico pensar que nunca nos pasará algo, no es preguntarse si va fallar, sino cuándo va a fallar!! es inminente el riego, por tal razón, para esos momento críticos, entre mejor preparados estemos menos serán las perdidas.”
Y preguntarse: ¿Tú sistema es realmente 24*7 los 365 días del año?
Y recordad esto: Un sistema seguro es aquel que siempre está disponible.
Referencias
https://blogs.gartner.com/andrew-lerner/2014/07/16/the-cost-of-downtime/
http://blog.ptsecurity.com/2017/08/web-application-vulnerability-research.html
https://msdn.microsoft.com/en-us/library/ee797245(v=cs.10).aspx
Autor: Ulises Lazarini